Einstieg
Was kann es zum Frauentag besseres geben, als einen Artikel über Apple zu schreiben? Tatsächlich war es so in den 90ern, dass diese Art von Computer in der Mehrzahl von weiblicher Kundschaft genutzt wurde. Lag es am knuffigen Aussehen vom “Mac”? Oder der einfachen, intuitiven Bedienung, die es damals ermöglichte, das nicht nur Nerds das Neuland entdecken?
Auch heute noch ist Apple denkbar einfach zu nutzen, stabil in der Qualität, und (das ist das Wichtigste) gar nicht mal mehr zu teuer
LLM Homelab
In den letzten Posts ging es im KI, wie sie weiter in unseren Alltag vordringt und immer einfacher zu nutzen ist. Fast täglich gibt es neue Rekorde und neue Funktionen bei den verschiedenen KI-Tools. Die Kommerzialisierung hinkt noch etwas hinterher, ddoch bald werden wir auch Werbeeinblendungen bei den Antworten von ChatGPT bekommen. Gute Idee also, die Sache mit dem LLM-Homelab weiter zu verfolgen.
Mein Hardware-Zoo zu Hause ist schon sehr veraltet. Es tut zwar noch für die eine oder andere Aufgabe oder für Backups. Für KI ist das alles nichts, da brauch man leistungsfähige Grafikkarten. Also habe ich mich auf die Suche gemacht, was gar nicht mal so einfach ist, wenn man kein Gamer ist und die letzten 30 Jahre keine neue Grafikkarte gekauft hat. Denn Grafikkarte, also GPU, muss für KI schon mal sein. Marktführer hier ist Nvidia, der seine Technologie weiterlizensiert, sodass ich mir die MSI GeForce RTX 3050 Ventus 2X XS 8G OC gekauft habe. Aber oh weh, die passte gar nicht in den Minisforum MS-01 rein, der ebenfalls neu angeschafft wurde (siehe nächster Beitrag). Bei den vielen Abkürzungen hätte man auf LP, für Low Profile, achten müssen, denn im MS-01 ist nur Platz für ein Slot, wobei die LP aber auch 2 statt 4 Slot hat. Irgendwie hätte man noch den Kühler umbaueen müssen oder eine RTX A2000 kaufen müssen. Die kostet aber auch “nur” 1000 Euro!. Nebenrecherche war dann noch die Tesla GPU, die in der Open Telekom Cloud verbaut wurden, 2015. Es folge noch eine längere Geschichte über die Produktentwicklung der Tesla Grafikkarte von 2011 bis 2022, verbunden natürlich mit den jeweiligen technischen Weiterentwicklungen. Bei eBay kann man solche Exemplare noch erwerben. Manche haben nicht mal einen PCIe-Anschluss, wer weiss wie die zu verlöten sind. Also alles irgendwie nichts, wenn man mal dran denkt, dass man nahezu 1000 Euro für eine Grafikkarte ausgibt. ChatGPT hat dann noch den Dell Precision 7620 Tower vorgeschlagen, also nochmal 1000 Euro. Alles für ein bisschen KI Gebastel.
Gefunden habe ich dann dieses Video:
Mac Mini
Mac Mini ist nochmal etwas kleiner als gedacht:

Ich habe mich für das Einsteiger Modell entschieden. Dieser verfügt auch über neuronale CPU M4 Chipsatz. Letztes Jahr angekündigt, heute schon auf meinem Küchentisch.
Es gibt noch stärkere Modelle, dir entsprechend teurer sind. Die Apple-Preise sind noch zu unterbieten, wenn man den Mini auf Amazon kauft:
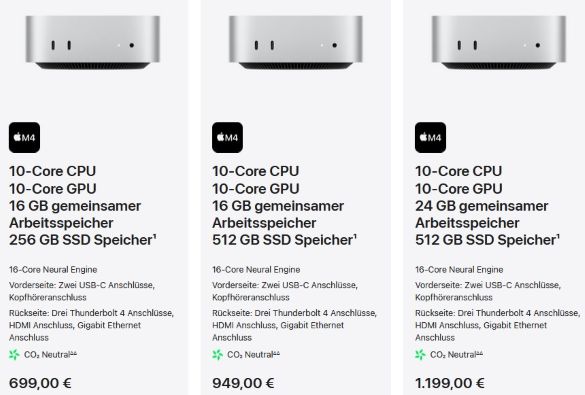
Betriebssystem ist ja schon installiert. Man brauch ein USB-C, um sich zu verbinden. Mit LAN-Kabel geht’s ins Heimnetzwerk. Aber natürlich hat der Mini auch WLAN.

Sehr schön. Ollama ist auch schon installiert und das Terminal grün gemacht. Die Schritt für Schritt Anleitung findet man oben im Video. Folgende Änderungen habe ich noch gemacht:
Bildschirmfreigabe
Ist in den Mac-Einstellungen zu aktivieren. Ebenso die Optionen, um mit VNC zuzugreifen. Ein Passwort für VNC ist zu vergeben und die erlaubten Benutzer, also ich. Dazu habe ich die Passworteingabe bei den Anmeldeoptionen entfernt und den Sperrbildschirm ausgeschalten, denn ich will nur per VNC zugreifen, bin der einzigste Benutzer und brauche hier die ganzen Sicherheitsfeatures nicht. Mac hat noch seine eigenen Standards, was VNC betrifft. RealVNC hat gut funktioniert. Nach den Änderungen auf dem Mac kann man im RealVNC seine IP-Adresse eingeben und kann sich mit ihm remote verbinden. Optionalerweise gibt man in den Netzwerkeinstellungen eine statische IP-Adresse aus dem Heimnetzwerk statt DHCP. Sonst ändert sich die IP laufend.
Ollama
Ollama hat einen Installer für Mac, der die Applikation automatisch startet. Leider steht die Listenaddress auf 127.0.0.1 und wir wollen unseren Ollama-Dienst im Heimnetzwerk exposen. Dazu stoppen wir Ollama, auch in Mac-Einstellungen bei “Bei der Anmeldung öffnen” deaktivieren wir den Dienst. Stattdessen erstellen wir im Terminal die Datei .zshrc mit dem Inhalt
export OLLAMA_HOST=http://0.0.0.0:11434
ollama serve
Damit wird Ollama mit der Listenaddress 0.0.0.0 gestartet und ist von allen anderen Rechnern im Heimnetzwerk erreichbar.
Hinweis: alle anderen Optionen mit launchctl und lokalen env-Profilen waren nicht erfolgreich. Dieses ist der einfachste Weg und wenn man Ollama nicht exposen will, brauch man das auch nicht.
Docker Desktop
Informationen und Links zur Installation findet man auf der Docker Seite. Ein Account bei Docker ist nicht notwendig. Kann man bei der Installation alles skippen.
Wichtig ist, dass Docker Desktop in dem Mac-Einstellungen bei “Bei der Anmeldung öffnen” gelistet bzw. aktiviert ist. Damit wird Docker Desktop immer gestartet. Kann man auch mit docker ps im Terminal testen.
OpenWebUI
Die erstaunlichste Neuerung seit meiner letzten Recherche ist das OpenWebUI. Bislang haben wir uns am Ollama Chatprompt zu schaffen gemacht. Oder mit Gradio eine relativ einfache Python-Applikation zum Leben erweckt, um mit unserem LLM kommunzieren zu können. Das lief im Kubernetes-Cluster und mit ein paar Änderungen an der ConfigMap und dem Restart konnte man auch ein anderes Model benutzen. Im Ansatz ohne RAG geht das viel einfacher.
OpenWebUI ist eine Web-Applikation ähnlich wie die Webseite von ChatGPT. Man hat ein grosses Textfeld, kann verschiedene Model auswählen (die die per Ollama gepullt sind), und hat einen Chatverlauf an der linken Seite. Zu installieren ist das ganze einfach mit dem docker run Befehl wahlweise mit oder ohne Multi-User-Mode. Also etwa
docker run -d -p 3000:8080 -e WEBUI_AUTH=False -v open-webui:/app/backend/data --restart-always --name open-webui ghcr.io/open-webui/open-webui:main
Fortan kann man aus dem Heimnetzwerk auf das LLM auf dem Mini zugreifen, also etwa http://mac.home.lan:3000 oder http://192.168.0.24:3000, wer kein DNS betreibt.
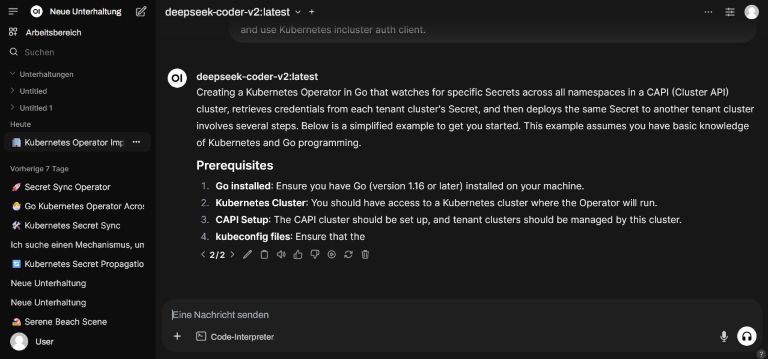
Na, sieht das nicht gut aus? Wie zu sehen, wird viel mit Programmierung gearbeitet und die KI dazu befragt. Im Gegensatz zu den bisherigen Tests ohne GPU sind die Antworten hier schneller und präziser. Ich kann zwischen verschiedenen Model wechseln oder diese parallel befragen. Models von 7/8G bis 16 G sollten problemlos laufen, wenn man die Resourcen seines Minis kennt. Wenn man vorhat, tiefer in die Materie einzusteigen und grössere LLM laufen zu lassen, kann man einfach einen grösseren Mini wählen. Wie im Video oben beschrieben, hat der Mac einen guten Wiederverkaufswert und ist auch für andere Aufgaben (insbesondere mit Docker Desktop) gut zu gebrauchen.
Überzeugend war auf jeden Fall die einfache Handhabung des Minis. Nach der Bestellung war das Gerät nach einem Tag geliefert. Dank einer USB-C-Dockingstation, an dem sonst der Mac Laptop hängt, war auch die Ersteinrichtung kein Problem. Docker, Ollama und OpenWebUI sind im Handumdrehen gebrauchsfertig. Mit dem Ollama und dem Remote-Zugriff war etwas Fummelei, brauch aber auch nicht jeder in dieser Konstellation.
Rundum zu Empfehlen, nicht nur für Frauen :-)
Viel Spass