Einstieg
Wenn man in der IT verschiedene Dienste laufen lässt, will man meistens auch wissen, ob diese denn auch laufen. Um das nicht jedes Mal selbst zu überprüfen, gibt es Monitoring-Systeme. Solche Systeme gibt es in beliebiger Grösse und man kann auch beliebig viel Resourcen, Zeit und Geld reinstecken. Unter Umständen ist das Monitoring-System grösser als die eigentliche Anwendung. Minimal gehalten ist es nur ein Oneliner:
while true; do p=$(ping -q -c 1 -w 1 blog.eumel.de) || echo "FAILED"; sleep 1;done
Anforderungen
Okay, der Ping-Oneliner informiert mich auf der Text-Console, ob ein Server erreichbar ist und gibt FAILED aus, wenn dem nicht so ist. Vielleicht darf es auch ein bisschen mehr sein.
Hier meine Liste nach Prio:
- Mein Webserver und Mailserver ist auf den Protokollen icmp, tcp und den Diensten https, smtp, imap, pop3 erreichbar
- SSL Zertifikate sind gültig und nicht abgelaufen
-
Informiere mich per SMS, wenn dem nicht so ist
- Die Festplatte des Linux-Servers ist nicht zu 100% voll
- Memory und CPU ist genug frei
- Anzahl der Prozesse ist im Rahmen, keine Zombi-Prozesse
- Alle LXD-Container laufen, ZFS hat genug freien Speicher
- Security-Updates sind verfügbar (kritisch/nicht kritisch)
- Informiere mich per E-Mail, wenn dem nicht so ist
Letzteres ist gar keine Anforderung, da ich regelmässig etliche tausend E-Mails lösche, die jeder LXD-Container verschickt, weil er mal ein Debian-Package updaten möchte. Wenn der Dienst “vor Kunde” nicht verfügbar ist, brauche ich allerdings schon eine Notifizierung und die ist nicht unbedingt nur E-Mail.
Icinga
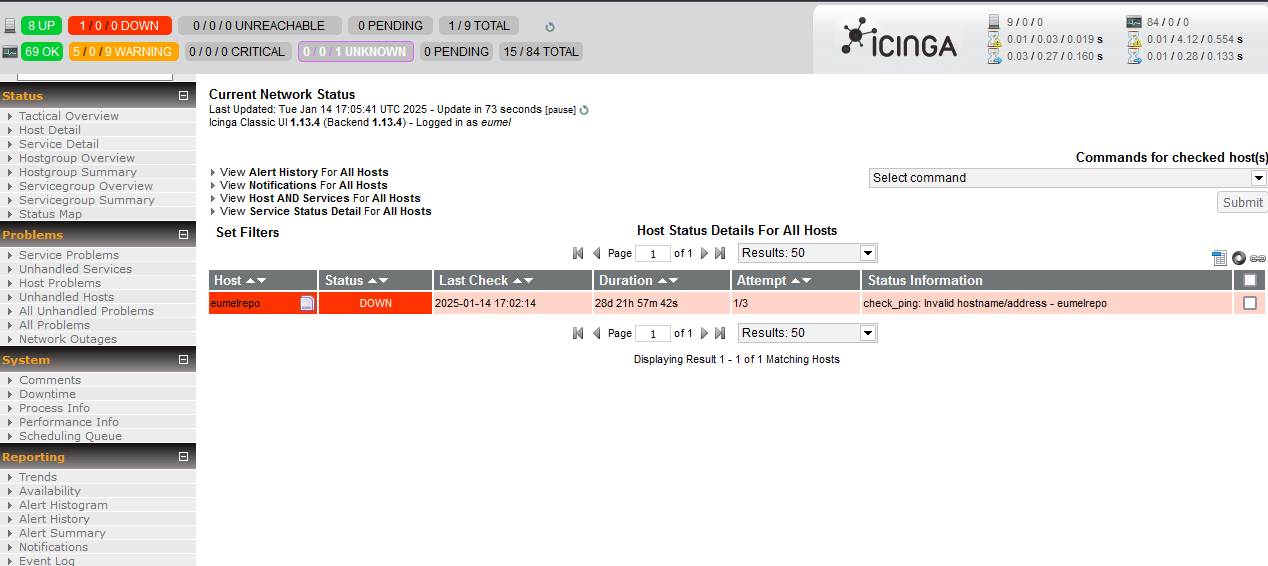
Icinga ist ein Fork von Nagios, ein Monitoring-System aus dem letzten Jahrtausend. Es ist auch heute noch relativ häufig im Einsatz. Die Architektur besteht aus dem Icinga-Server mit Web-Frontend und den sogenannten NRPE-Agenten. Diese kann der Icinga mit einem speziellen Protokoll abfragen und bekommt Statusinformationen, etwa “läuft Prozess xyz?”. Es existiert eine grosse Azahl von Plugins, die quasi schon vorgefertigt Dienste abfragen können, etwa SMTP. Aus der Geschichte der Zeit sind diese Plugin in bash geschrieben, oder die meisten in Perl. Und da fängt das Problem auch an. Ab Ubuntu 20.04 gabs schon die ersten Inkompatibilitäten von bereitgestellten Perl-Versionen und verfügbaren Plugin-Paketen. Es funktionierte noch, wenn man alte universe-Pakete noch irgendwo fand und die lokal sicherte. Ab Ubuntu 24.04 ist damit aber Schluss. Der Zeit- und Versionsunterschied ist einfach zu gross. Was tun? Von Icinga 1 nach Icinga 2 migrieren und damit einen Burst von Resourcen starten wie eigene Datenbank und dann natürlich alle Checks umschreiben und nach neuen Plugins suchen? Viele Tests haben sich als überflüssig rausgestellt, werden gar nicht genutzt. Die Liste der harten Anforderungen ist doch recht kurz und rechtfertigt kein grosses Monitoring-System. Also: weg damit!
Prometheus
Prometheus ist der de facto Standard in der cloud-nativen Monitoring-Welt. Es gibt wieder einen zentralen Server. Das Web-Frontend ist eher spartanisch. Deswegen wird meist Grafana eingesetzt, um Metriken zu visualisieren. Dazu gibt es eine grosse Zahl von frei verfügbaren Dashboards. Die Daten bekommt Prometheus von sogenanten Scrape-Endpunkten, die er in einem vorgegeben Format über http abfragen kann. Viele Applikationen bieten so einen /metric-Endpunkt an und stellen dort eine Vielzahl von Metriken bereit, die den aktuellen Zustand der Applikation beschreiben. Durch die grosse Community um Prometheus gibt es aber auch eine Vielzahl von Exportern, die diese Aufgabe übernehmen. Github listet über 2000.
Rant: Witzigerweise gibt es auch einen Nagios-Exporter für Prometheus und Icinga XI unterstützt jetzt auch Prometheus-Metriken. Muss man wissen, ob man sein Monitoring ein bisschen umstellt und dann doppelte Arbeit hat.
Exporter
Folgende Exporter wollen wir verwenden:
- Node-Exporter Ein sehr mächtiger Exporter, der uns hunderte von Metriken zu unserem Linux-Server bereitgestellt, sei es CPU-Metriken, Memory-Verbrauch, Festplattenbelegung usw.
- LXD-Exporter LXD ist im Einsatz und hier der passende Exporter-Fork, läuft mit Incus/LXD 4.0
- ZFS-Exporter Liefert Metriken zum ZFS-Pool unter LXD, wird aber teilweise schon durch den Node-Exporter zur Verfügung gestellt.
- Blackbox-Exporter Testet Dienste “von aussen” (Blackbox), etwa Webseiten oder Mailserver
Ausserdem liefert Prometheus ebenfalls Metriken über den eingebauten Exporter, wir können ihn also auch selber abfragen.
Prom-LXD
Unser neues Zielsystem ist ein LXD-Container mit Ubuntu 24.04. Bislang wurde die Konfiguration mit Puppet ausgerollt. Hier gab es aber in Puppet 8 auch Breaking Changes, die zusätzlichen Verwaltungsaufwand bedeuten. Wir werden die Konfiguration direkt aus dem Git als Debian-Package aufs System bringen. In einer Gitlab-CI-Pipeline geht das mit
stages:
- build
package:
stage: build
variables:
BRANCH: $CI_COMMIT_REF_NAME
DATE: `date +%s`
script:
- apt-get -y install ruby ruby-dev rubygems build-essential
- gem install fpm
- fpm -s dir -t deb -d 'puppet' -v "01-${BRANCH}-${DATE}" \
--deb-no-default-config-files \
-n eumelprom \
--iteration 1 \
-x .git \
--description "Configuration package for eumelnet LXD" \
--prefix / . || exit 1
Den LXD-Container starten wir mit
lxc launch ubuntu:24.04 eumelprom
Wir kopieren mit lxc file push unser debian-Paket in den LXD Container. Oder über ein internes Apt-Repo ist das Paket verfügbar. Es enthält folgende Dateien:
index.html - diese Datei stammt von prometheus-dashboard und ist unser angepasstes Template dafür
alertmanager.yaml - diese Datei beinhaltet die Konfiguration des Alertmanagers und wie Alarme behandelt werden sollen. Wir schicken zum Beispiel kritische Alarme an einen Webhook.
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 10m
repeat_interval: 12h
receiver: "null"
routes:
- continue: true
group_interval: 5m
group_wait: 30s
matchers:
- severity="critical"
receiver: 'web.hook'
receivers:
- name: "null"
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:9000/hooks/twilio-webhook'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance']blackbox.yaml - das ist die default Konfigurationsdatei des Blackbox-Exporters. Man kann nicht genutzte Module dort auch entfernen oder anpassen:
# https://github.com/prometheus/blackbox_exporter/blob/master/CONFIGURATION.md
modules:
http_2xx:
prober: http
timeout: 5s
http:
preferred_ip_protocol: "ip4"
https_2xx:
prober: http
timeout: 5s
http:
preferred_ip_protocol: "ip4"
fail_if_not_ssl: true
http_post_2xx:
prober: http
timeout: 5s
http:
method: POST
basic_auth:
username: "username"
password: "mysecret"
body_size_limit: 1MB
tcp_connect:
prober: tcp
timeout: 5s
pop3s_banner:
prober: tcp
tcp:
query_response:
- expect: "^+OK"
tls: true
tls_config:
insecure_skip_verify: false
smtp_starttls:
prober: tcp
timeout: 5s
tcp:
query_response:
- expect: "^220 "
- send: "EHLO prober\r"
- expect: "^250-STARTTLS"
- send: "STARTTLS\r"
- expect: "^220"
- starttls: true
- send: "EHLO prober\r"
- expect: "^250-AUTH"
- send: "QUIT\r"
icmp_test_v4:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: ip4
icmp_test_v6:
prober: icmp
timeout: 5s
icmp:
preferred_ip_protocol: ip6
dns_test:
prober: dns
timeout: 5s
dns:
query_name: eumelnet.de
preferred_ip_protocol: ip4
ip_protocol_fallback: false
validate_answer_rrs:
fail_if_matches_regexp: [test]eumelnet_rules.yaml - hier sind spezielle Alarmrules definiert, also Prometheus Queries, die den Alertmanager triggern sollen.
groups:
- name: eumelnet
labels:
team: eumelnet
rules:
- alert: HttpStatusNot200
expr: probe_http_status_code{} != 200
for: 10m
keep_firing_for: 5m
labels:
severity: critical
annotations:
summary: HTTP Status of {{ $labels.instance }} is not 200
- alert: HostOutOfMemory
expr: (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 < 10) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}
for: 2m
labels:
severity: warning
annotations:
summary: Host out of memory (instance {{ $labels.instance }})
description: "Node memory is filling up (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOutOfDiskSpace
expr: ((node_filesystem_avail_bytes * 100) / node_filesystem_size_bytes < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}
for: 2m
labels:
severity: warning
annotations:
summary: Host out of disk space (instance {{ $labels.instance }})
description: "Disk is almost full (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: PrometheusTargetMissing
expr: up == 0
for: 0m
labels:
severity: critical
annotations:
summary: Prometheus target missing (instance {{ $labels.instance }})
description: "A Prometheus target has disappeared. An exporter might be crashed.\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: PrometheusConfigurationReloadFailure
expr: prometheus_config_last_reload_successful != 1
for: 0m
labels:
severity: warning
annotations:
summary: Prometheus configuration reload failure (instance {{ $labels.instance }})
description: "Prometheus configuration reload error\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOutOfInodes
expr: (node_filesystem_files_free{fstype!="msdosfs"} / node_filesystem_files{fstype!="msdosfs"} * 100 < 10 and ON (instance, device, mountpoint) node_filesystem_readonly == 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}
for: 2m
labels:
severity: warning
annotations:
summary: Host out of inodes (instance {{ $labels.instance }})
description: "Disk is almost running out of available inodes (< 10% left)\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostHighCpuLoad
expr: (sum by (instance) (avg by (mode, instance) (rate(node_cpu_seconds_total{mode!="idle"}[2m]))) > 0.8) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}
for: 10m
labels:
severity: warning
annotations:
summary: Host high CPU load (instance {{ $labels.instance }})
description: "CPU load is > 80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: HostOomKillDetected
expr: (increase(node_vmstat_oom_kill[1m]) > 0) * on(instance) group_left (nodename) node_uname_info{nodename=~".+"}
for: 0m
labels:
severity: warning
annotations:
summary: Host OOM kill detected (instance {{ $labels.instance }})
description: "OOM kill detected\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: BlackboxSslCertificateWillExpireSoon
expr: 0 <= round((last_over_time(probe_ssl_earliest_cert_expiry[10m]) - time()) / 86400, 0.1) < 3
for: 0m
labels:
severity: critical
annotations:
summary: Blackbox SSL certificate will expire soon (instance {{ $labels.instance }})
description: "SSL certificate expires in less than 3 days\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
# https://samber.github.io/awesome-prometheus-alerts/rules.html
{% endhighlight %}
</details>
hooks.yaml - das ist die Konfigurationsdatei für den Webhook vom Alertmanager
<details>
{% highlight yaml %}
- id: twilio-webhook
execute-command: "/etc/eumelnet/twilio.sh"
command-working-directory: "/tmp"
pass-arguments-to-command:
- source: entire-payload
name: alertstwilio.sh - das ist die Datei, die vom Webhook ausgeführt wird. Seit Jahren im Einsatz ist Twilio, ein API-gesteuerter Router von text2sms oder text2voice Nachrichten. Mit diesem Script wird eine SMS versendet man dem vom Webhook und dem Alertmanager übermitelten Daten:
#!/bin/bash
type curl >/dev/null 2>&1 || { echo >&2 "I require curl but it's not installed. Aborting."; exit 1; }
type jq >/dev/null 2>&1 || { echo >&2 "I require jq but it's not installed. Aborting."; exit 1; }
gateway_uri="https://api.twilio.com/2010-04-01/Accounts/ACxxxxxx/Messages.json"
identifier="ACxxxx:yyyy"
from="From=%2B184812345"
to="To=%2B4917212345"
logger eumelprom notifycmd exec
echo "$1" | jq -c '.alerts[]' | while read -r alert; do
summary=$(echo "$alert" | jq -r '.annotations.summary')
startsAt=$(echo "$alert" | jq -r '.startsAt')
instance=$(echo "$alert" | jq -r '.labels.instance')
severity=$(echo "$alert" | jq -r '.labels.severity')
message="EUMELPROM ALERT: $summary - $instance - $startsAt"
echo $message
exit
curl -X POST $gateway_uri \
-u $identifier \
-d $from \
-d $to \
--data-urlencode "Body=$message" > /dev/null 2>&1
doneprometheus.yaml - Die Kernkonfiguration des Prometheus. Zum Einen wird der Endpunkt des Alertmanagers angegeben, an den Alarme aus den Metrik-Rules geschickt werden soll. Die Rule-Datei wird dazu included.
Zum Anderen sind die Scrape-Endpunkte der Exporter angegeben, also von wo die Daten bezogen werden.
Im Beispiel unten laufen der ZFS- und LXD-Exporter auf dem Server und werden über das Default-Gateway des LXD-Servers angesprochen. Bei diesen Exportern ist auch darauf zu achten, dass der Listener nicht auf :<port> oder 0.0.0.0:<port> steht und Metriken so möglicherweise ins Internet exposed werden.
Den Node-Exporter haben wir auf dem LXD-Container installiert. Er könnte natürlich auch auf dem LXD-Server laufen und so noch zusätzliche Metriken liefern. Blackbox-Exporter läuft im LXD-Container, sowie auch Prometheus, Prometheus-Dashboard und Alertmanager.
global:
scrape_interval: 15s
evaluation_interval: 15s
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
rule_files:
- "eumelnet_rules.yaml"
scrape_configs:
- job_name: "zfs"
static_configs:
- targets: ["10.176.65.1:9134"]
- job_name: "lxd"
static_configs:
- targets: ["10.176.65.1:9472"]
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: 'node_exporter'
static_configs:
- targets: ['127.0.0.1:9100']
- job_name: 'blackbox_exporter'
static_configs:
- targets: ['127.0.0.1:9115']
- job_name: 'blackbox_https'
metrics_path: /probe
params:
module: [https_2xx]
static_configs:
- targets:
- blog.eumel.de
- www.eumel.de
- www.eumel.de:24443
- ebooks.eumel.de
- www.schnattel.net
- webmail.eumelnet.de
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
- job_name: 'blackbox_http'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- zuni.eumelnet.de:8090
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
- job_name: 'blackbox_icmp_v4'
metrics_path: /probe
params:
module: [icmp_test_v4]
static_configs:
- targets:
- jambo.eumelnet.de
- zuni.eumelnet.de
- uucp.gnuu.de
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
- job_name: 'blackbox_icmp_v6'
metrics_path: /probe
params:
module: [icmp_test_v6]
static_configs:
- targets:
- jambo.eumelnet.de
- zuni.eumelnet.de
- uucp.gnuu.de
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
- job_name: 'blackbox_dns'
metrics_path: /probe
params:
module: [dns_test]
static_configs:
- targets:
- jambo.eumelnet.de
- zuni.eumelnet.de
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
- job_name: 'blackbox_tcp'
metrics_path: /probe
params:
module: [tcp_connect]
static_configs:
- targets:
- zuni.eumelnet.de:110
- zuni.eumelnet.de:143
- zuni.eumelnet.de:993
- zuni.eumelnet.de:995
- uucp.gnuu.de:540
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
- job_name: 'blackbox_smtp'
metrics_path: /probe
params:
module: [smtp_starttls]
static_configs:
- targets:
- vip.eumelnet.de:25
- uucp.gnuu.de:25
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115install.sh - diese Datei führen wir im LXD-Container aus
#!/bin/sh
# https://github.com/rouge-ruby/rouge/wiki/List-of-supported-languages-and-lexers
PROM_VERSION=3.1.0
BLACK_VERSION=0.25.0
NODE_VERSION=1.8.2
ALERT_VERSION=0.27.0
WEBHOOK_VERSION=2.8.2
DASHBOARD_VERSION=1.0.8
mkdir -p /data
mkdir -p eumelprom
cd eumelprom
# prometheus
curl -s -LO https://github.com/prometheus/prometheus/releases/download/v${PROM_VERSION}/prometheus-${PROM_VERSION}.linux-amd64.tar.gz
tar xfz prometheus-${PROM_VERSION}.linux-amd64.tar.gz
cp prometheus-${PROM_VERSION}.linux-amd64/prometheus /usr/local/bin/prometheus
chmod +x /usr/local/bin/prometheus
# blackbox_exporter
curl -s -LO https://github.com/prometheus/blackbox_exporter/releases/download/v${BLACK_VERSION}/blackbox_exporter-${BLACK_VERSION}.linux-amd64.tar.gz
tar xfz blackbox_exporter-${BLACK_VERSION}.linux-amd64.tar.gz
cp blackbox_exporter-${BLACK_VERSION}.linux-amd64/blackbox_exporter /usr/local/bin/blackbox_exporter
chmod +x /usr/local/bin/blackbox_exporter
# node_exporter
curl -s -LO https://github.com/prometheus/node_exporter/releases/download/v${NODE_VERSION}/node_exporter-${NODE_VERSION}.linux-amd64.tar.gz
tar xfz node_exporter-${NODE_VERSION}.linux-amd64.tar.gz
cp node_exporter-${NODE_VERSION}.linux-amd64/node_exporter /usr/local/bin/node_exporter
chmod +x /usr/local/bin/node_exporter
# alertmanager
curl -s -LO https://github.com/prometheus/alertmanager/releases/download/v${ALERT_VERSION}/alertmanager-${ALERT_VERSION}.linux-amd64.tar.gz
tar xfz alertmanager-${ALERT_VERSION}.linux-amd64.tar.gz
cp alertmanager-${ALERT_VERSION}.linux-amd64/alertmanager /usr/local/bin/alertmanager
chmod +x /usr/local/bin/alertmanager
# webhook
curl -s -LO https://github.com/adnanh/webhook/releases/download/${WEBHOOK_VERSION}/webhook-linux-amd64.tar.gz
tar xfz webhook-linux-amd64.tar.gz
cp webhook-linux-amd64/webhook /usr/local/bin/webhook
chmod +x /usr/local/bin/webhook
# dashboard
curl -s -LO https://github.com/eumel8/prometheus-dashboard/releases/download/${DASHBOARD_VERSION}/prometheus-dashboard-${DASHBOARD_VERSION}-linux-amd64.tar.gz
tar xfz prometheus-dashboard-${DASHBOARD_VERSION}-linux-amd64.tar.gz
cp prometheus-dashboard /usr/local/bin/prometheus-dashboard
chmod +x /usr/local/bin/prometheus-dashboard
# remove tmp
cd ..
rm -rf eumelprom
# systemd prometheus
cat << EOF > /etc/systemd/system/prometheus.service
[Unit]
Description=Eumelnet Prometheus
After=network.target
[Service]
ExecStart=/usr/local/bin/prometheus --config.file=/etc/eumelnet/prometheus.yaml --storage.tsdb.path=/data
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable prometheus.service
sudo systemctl start prometheus.service
# systemd alertmanager
cat << EOF > /etc/systemd/system/alertmanager.service
[Unit]
Description=Eumelnet Alertmanager
After=network.target
[Service]
ExecStart=/usr/local/bin/alertmanager --config.file=/etc/eumelnet/alertmanager.yaml
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable alertmanager.service
sudo systemctl start alertmanager.service
# systemd blackbox-exporter
cat << EOF > /etc/systemd/system/blackbox_exporter.service
[Unit]
Description=Eumelnet Blackbox Exporter
After=network.target
[Service]
ExecStart=/usr/local/bin/blackbox_exporter --config.file=/etc/eumelnet/blackbox.yaml
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable blackbox_exporter.service
sudo systemctl start blackbox_exporter.service
# systemd node-exporter
cat << EOF > /etc/systemd/system/node_exporter.service
[Unit]
Description=Eumelnet Node Exporter
After=network.target
[Service]
ExecStart=/usr/local/bin/node_exporter
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable node_exporter.service
sudo systemctl start node_exporter.service
# systemd webhook
cat << EOF > /etc/systemd/system/webhook.service
[Unit]
Description=Eumelnet Webhook
After=network.target
[Service]
ExecStart=/usr/local/bin/webhook -hooks /etc/eumelnet/hooks.yaml -verbose
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable webhook.service
sudo systemctl start webhook.service
# systemd prometheus-dashboard
cat << EOF > /etc/systemd/system/prometheus-dashboard.service
[Unit]
Description=Eumelnet Prometheus Dashboard
After=network.target
[Service]
ExecStart=/usr/local/bin/prometheus-dashboard --indexTemplate /etc/eumelnet/index.html
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable prometheus-dashboard.service
sudo systemctl start prometheus-dashboard.servicehost.sh - Diese Datei führen wir auf dem LXD-Server aus
#!/bin/sh
#
LXD_EXPORTER_VERSION=1.0.0
ZFS_EXPORTER_VERSION=2.3.4
mkdir -p eumelprom
cd eumelprom
# lxd_exporter
curl -s -LO https://github.com/eumel8/lxd_exporter/releases/download/${LXD_EXPORTER_VERSION}/lxd_exporter-${LXD_EXPORTER_VERSION}-linux-amd64.tar.gz
tar xfz lxd_exporter-${LXD_EXPORTER_VERSION}-linux-amd64.tar.gz
cp lxd_exporter /usr/local/bin/lxd_exporter
chmod +x /usr/local/bin/lxd_exporter
# zfs_exporter
curl -s -LO https://github.com/pdf/zfs_exporter/releases/download/v${ZFS_EXPORTER_VERSION}/zfs_exporter-${ZFS_EXPORTER_VERSION}.linux-amd64.tar.gz
tar xfz zfs_exporter-${ZFS_EXPORTER_VERSION}.linux-amd64.tar.gz
cp zfs_exporter-${ZFS_EXPORTER_VERSION}.linux-amd64/zfs_exporter /usr/local/bin/zfs_exporter
chmod +x /usr/local/bin/zfs_exporter
# remove tmp
cd ..
rm -rf eumelprom
# systemd lxd-exporter
cat << EOF > /etc/systemd/system/lxd_exporter.service
[Unit]
Description=Eumelnet LXD Exporter
After=network.target
[Service]
ExecStart=/usr/local/bin/lxd_exporter --listen=10.176.65.1
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable lxd_exporter.service
sudo systemctl start lxd_exporter.service
# systemd zfs-exporter
cat << EOF > /etc/systemd/system/zfs_exporter.service
[Unit]
Description=Eumelnet ZFS Exporter
After=network.target
[Service]
ExecStart=/usr/local/bin/zfs_exporter --web.listen-address=10.176.65.1:9134
Restart=on-failure
User=root
Group=root
[Install]
WantedBy=multi-user.target
EOF
#
sudo systemctl daemon-reload
sudo systemctl enable zfs_exporter.service
sudo systemctl start zfs_exporter.serviceFertig